
| | |  مشاهده منبع در GitHub مشاهده منبع در GitHub | |
بررسی اجمالی
این آموزش تقویت داده ها را نشان می دهد: تکنیکی برای افزایش تنوع مجموعه آموزشی شما با اعمال تبدیل های تصادفی (اما واقعی) مانند چرخش تصویر.
شما یاد خواهید گرفت که چگونه افزایش داده را به دو روش اعمال کنید:
- از لایه های پیش پردازش Keras، مانند
tf.keras.layers.Resizing،tf.keras.layers.Rescaling،tf.keras.layers.RandomFlipوtf.keras.layers.RandomRotationاستفاده کنید. - از روشهای
tf.image، مانندtf.image.flip_left_right،tf.image.rgb_to_grayscale،tf.image.adjust_brightness،tf.image.central_crop، وtf.image.stateless_random*استفاده کنید.
برپایی
import matplotlib.pyplot as plt
import numpy as np
import tensorflow as tf
import tensorflow_datasets as tfds
from tensorflow.keras import layers
یک مجموعه داده را دانلود کنید
این آموزش از مجموعه داده tf_flowers استفاده می کند. برای راحتی، مجموعه داده را با استفاده از TensorFlow Datasets دانلود کنید. اگر میخواهید با روشهای دیگر وارد کردن دادهها آشنا شوید، آموزش بارگذاری تصاویر را بررسی کنید.
(train_ds, val_ds, test_ds), metadata = tfds.load(
'tf_flowers',
split=['train[:80%]', 'train[80%:90%]', 'train[90%:]'],
with_info=True,
as_supervised=True,
)
مجموعه داده گل دارای پنج کلاس است.
num_classes = metadata.features['label'].num_classes
print(num_classes)
5
بیایید یک تصویر را از مجموعه داده بازیابی کنیم و از آن برای نشان دادن افزایش داده ها استفاده کنیم.
get_label_name = metadata.features['label'].int2str
image, label = next(iter(train_ds))
_ = plt.imshow(image)
_ = plt.title(get_label_name(label))
2022-01-26 05:09:18.712477: W tensorflow/core/kernels/data/cache_dataset_ops.cc:768] The calling iterator did not fully read the dataset being cached. In order to avoid unexpected truncation of the dataset, the partially cached contents of the dataset will be discarded. This can happen if you have an input pipeline similar to `dataset.cache().take(k).repeat()`. You should use `dataset.take(k).cache().repeat()` instead.

از لایه های پیش پردازش Keras استفاده کنید
تغییر اندازه و تغییر مقیاس
میتوانید از لایههای پیشپردازش Keras برای تغییر اندازه تصاویر خود به شکل ثابت (با tf.keras.layers.Resizing ) و برای تغییر مقیاس مقادیر پیکسل (با tf.keras.layers.Rescaling ) استفاده کنید.
IMG_SIZE = 180
resize_and_rescale = tf.keras.Sequential([
layers.Resizing(IMG_SIZE, IMG_SIZE),
layers.Rescaling(1./255)
])
شما می توانید نتیجه اعمال این لایه ها را روی یک تصویر مجسم کنید.
result = resize_and_rescale(image)
_ = plt.imshow(result)
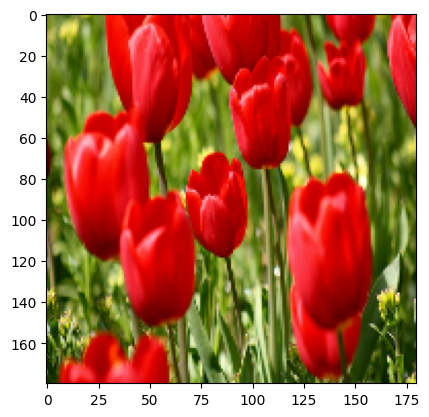
بررسی کنید که پیکسل ها در محدوده [0, 1] قرار دارند:
print("Min and max pixel values:", result.numpy().min(), result.numpy().max())
Min and max pixel values: 0.0 1.0
افزایش داده ها
میتوانید از لایههای پیشپردازش Keras برای تقویت دادهها نیز استفاده کنید، مانند tf.keras.layers.RandomFlip و tf.keras.layers.RandomRotation .
بیایید چند لایه پیش پردازش ایجاد کنیم و آنها را به طور مکرر روی همان تصویر اعمال کنیم.
data_augmentation = tf.keras.Sequential([
layers.RandomFlip("horizontal_and_vertical"),
layers.RandomRotation(0.2),
])
# Add the image to a batch.
image = tf.expand_dims(image, 0)
plt.figure(figsize=(10, 10))
for i in range(9):
augmented_image = data_augmentation(image)
ax = plt.subplot(3, 3, i + 1)
plt.imshow(augmented_image[0])
plt.axis("off")
WARNING:matplotlib.image:Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). WARNING:matplotlib.image:Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). WARNING:matplotlib.image:Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). WARNING:matplotlib.image:Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). WARNING:matplotlib.image:Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). WARNING:matplotlib.image:Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). WARNING:matplotlib.image:Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). WARNING:matplotlib.image:Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). WARNING:matplotlib.image:Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).

لایههای پیشپردازش مختلفی وجود دارد که میتوانید از آنها برای تقویت دادهها استفاده کنید، از جمله tf.keras.layers.RandomContrast ، tf.keras.layers.RandomCrop ، tf.keras.layers.RandomZoom ، و موارد دیگر.
دو گزینه برای استفاده از لایه های پیش پردازش Keras
دو راه برای استفاده از این لایههای پیشپردازش، با معاوضههای مهم وجود دارد.
گزینه 1: لایه های پیش پردازش را بخشی از مدل خود کنید
model = tf.keras.Sequential([
# Add the preprocessing layers you created earlier.
resize_and_rescale,
data_augmentation,
layers.Conv2D(16, 3, padding='same', activation='relu'),
layers.MaxPooling2D(),
# Rest of your model.
])
در این مورد باید به دو نکته مهم توجه کرد:
افزایش داده روی دستگاه، همزمان با بقیه لایههای شما اجرا میشود و از شتاب GPU بهره میبرد.
هنگامی که مدل خود را با استفاده از
model.saveصادر می کنید، لایه های پیش پردازش به همراه بقیه مدل شما ذخیره می شوند. اگر بعداً این مدل را اجرا کنید، به طور خودکار تصاویر را استاندارد می کند (با توجه به پیکربندی لایه های شما). این می تواند شما را از تلاش برای پیاده سازی مجدد آن منطق سمت سرور نجات دهد.
گزینه 2: لایه های پیش پردازش را به مجموعه داده خود اعمال کنید
aug_ds = train_ds.map(
lambda x, y: (resize_and_rescale(x, training=True), y))
با این رویکرد، از Dataset.map برای ایجاد مجموعه داده ای استفاده می کنید که دسته هایی از تصاویر تقویت شده را به دست می دهد. در این مورد:
- افزایش داده ها به صورت ناهمزمان در CPU اتفاق می افتد و غیر مسدود کننده است. میتوانید با استفاده از
Dataset.prefetchکه در زیر نشان داده شده است، آموزش مدل خود را روی GPU با پیش پردازش دادهها همپوشانی کنید. - در این مورد، وقتی
Model.saveرا فراخوانی میکنید، لایههای پیشپردازش با مدل صادر نمیشوند. شما باید آنها را قبل از ذخیره کردن آن به مدل خود وصل کنید یا آن ها را در سمت سرور اجرا کنید. پس از آموزش، می توانید لایه های پیش پردازش را قبل از صادرات وصل کنید.
می توانید نمونه ای از گزینه اول را در آموزش طبقه بندی تصاویر بیابید. بیایید گزینه دوم را در اینجا نشان دهیم.
لایه های پیش پردازش را روی مجموعه داده ها اعمال کنید
مجموعه دادههای آموزش، اعتبارسنجی و آزمایش را با لایههای پیشپردازش Keras که قبلا ایجاد کردهاید، پیکربندی کنید. همچنین مجموعه دادهها را برای عملکرد پیکربندی میکنید، با استفاده از خواندن موازی و واکشی اولیه بافر برای تولید دستههایی از دیسک بدون مسدود شدن ورودی/خروجی. ( با راهنمای tf.data API عملکرد مجموعه داده را در بخش عملکرد بهتر بیاموزید .)
batch_size = 32
AUTOTUNE = tf.data.AUTOTUNE
def prepare(ds, shuffle=False, augment=False):
# Resize and rescale all datasets.
ds = ds.map(lambda x, y: (resize_and_rescale(x), y),
num_parallel_calls=AUTOTUNE)
if shuffle:
ds = ds.shuffle(1000)
# Batch all datasets.
ds = ds.batch(batch_size)
# Use data augmentation only on the training set.
if augment:
ds = ds.map(lambda x, y: (data_augmentation(x, training=True), y),
num_parallel_calls=AUTOTUNE)
# Use buffered prefetching on all datasets.
return ds.prefetch(buffer_size=AUTOTUNE)
train_ds = prepare(train_ds, shuffle=True, augment=True)
val_ds = prepare(val_ds)
test_ds = prepare(test_ds)
یک مدل تربیت کنید
برای کامل بودن، اکنون یک مدل را با استفاده از مجموعه داده هایی که به تازگی آماده کرده اید آموزش می دهید.
مدل متوالی از سه بلوک کانولوشن ( tf.keras.layers.Conv2D ) با یک لایه تجمع حداکثر ( tf.keras.layers.MaxPooling2D ) در هر یک از آنها تشکیل شده است. یک لایه کاملاً متصل ( tf.keras.layers.Dense ) با 128 واحد در بالای آن وجود دارد که توسط یک تابع فعال سازی ReLU ( 'relu' ) فعال می شود. این مدل برای دقت تنظیم نشده است (هدف این است که مکانیک را به شما نشان دهیم).
model = tf.keras.Sequential([
layers.Conv2D(16, 3, padding='same', activation='relu'),
layers.MaxPooling2D(),
layers.Conv2D(32, 3, padding='same', activation='relu'),
layers.MaxPooling2D(),
layers.Conv2D(64, 3, padding='same', activation='relu'),
layers.MaxPooling2D(),
layers.Flatten(),
layers.Dense(128, activation='relu'),
layers.Dense(num_classes)
])
تابع از دست دادن tf.keras.optimizers.Adam و tf.keras.losses.SparseCategoricalCrossentropy را انتخاب کنید. برای مشاهده دقت آموزش و اعتبارسنجی برای هر دوره آموزشی، آرگومان metrics را به Model.compile کنید.
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
قطار برای چند دوره:
epochs=5
history = model.fit(
train_ds,
validation_data=val_ds,
epochs=epochs
)
Epoch 1/5 92/92 [==============================] - 13s 110ms/step - loss: 1.2768 - accuracy: 0.4622 - val_loss: 1.0929 - val_accuracy: 0.5640 Epoch 2/5 92/92 [==============================] - 3s 25ms/step - loss: 1.0579 - accuracy: 0.5749 - val_loss: 0.9711 - val_accuracy: 0.6349 Epoch 3/5 92/92 [==============================] - 3s 26ms/step - loss: 0.9677 - accuracy: 0.6291 - val_loss: 0.9764 - val_accuracy: 0.6431 Epoch 4/5 92/92 [==============================] - 3s 25ms/step - loss: 0.9150 - accuracy: 0.6468 - val_loss: 0.8906 - val_accuracy: 0.6431 Epoch 5/5 92/92 [==============================] - 3s 25ms/step - loss: 0.8636 - accuracy: 0.6604 - val_loss: 0.8233 - val_accuracy: 0.6730
loss, acc = model.evaluate(test_ds)
print("Accuracy", acc)
12/12 [==============================] - 5s 14ms/step - loss: 0.7922 - accuracy: 0.6948 Accuracy 0.6948229074478149
افزایش داده های سفارشی
شما همچنین می توانید لایه های افزایش داده های سفارشی ایجاد کنید.
این بخش از آموزش دو روش برای انجام این کار را نشان می دهد:
- ابتدا یک لایه
tf.keras.layers.Lambdaایجاد می کنید. این یک راه خوب برای نوشتن کد مختصر است. - بعد، یک لایه جدید از طریق subclassing می نویسید که به شما کنترل بیشتری می دهد.
هر دو لایه به طور تصادفی رنگ های یک تصویر را بر اساس برخی احتمالات معکوس می کنند.
def random_invert_img(x, p=0.5):
if tf.random.uniform([]) < p:
x = (255-x)
else:
x
return x
def random_invert(factor=0.5):
return layers.Lambda(lambda x: random_invert_img(x, factor))
random_invert = random_invert()
plt.figure(figsize=(10, 10))
for i in range(9):
augmented_image = random_invert(image)
ax = plt.subplot(3, 3, i + 1)
plt.imshow(augmented_image[0].numpy().astype("uint8"))
plt.axis("off")
2022-01-26 05:09:53.045204: W tensorflow/compiler/xla/service/gpu/llvm_gpu_backend/gpu_backend_lib.cc:399] target triple not found in the module 2022-01-26 05:09:53.045264: W tensorflow/compiler/xla/service/gpu/llvm_gpu_backend/gpu_backend_lib.cc:399] target triple not found in the module 2022-01-26 05:09:53.045312: W tensorflow/compiler/xla/service/gpu/llvm_gpu_backend/gpu_backend_lib.cc:399] target triple not found in the module 2022-01-26 05:09:53.045369: W tensorflow/compiler/xla/service/gpu/llvm_gpu_backend/gpu_backend_lib.cc:399] target triple not found in the module 2022-01-26 05:09:53.045418: W tensorflow/compiler/xla/service/gpu/llvm_gpu_backend/gpu_backend_lib.cc:399] target triple not found in the module 2022-01-26 05:09:53.045467: W tensorflow/compiler/xla/service/gpu/llvm_gpu_backend/gpu_backend_lib.cc:399] target triple not found in the module 2022-01-26 05:09:53.045511: W tensorflow/compiler/xla/service/gpu/llvm_gpu_backend/gpu_backend_lib.cc:399] target triple not found in the module 2022-01-26 05:09:53.047630: W tensorflow/compiler/xla/service/gpu/llvm_gpu_backend/gpu_backend_lib.cc:399] target triple not found in the module

سپس، یک لایه سفارشی را با زیر کلاس بندی پیاده سازی کنید:
class RandomInvert(layers.Layer):
def __init__(self, factor=0.5, **kwargs):
super().__init__(**kwargs)
self.factor = factor
def call(self, x):
return random_invert_img(x)
_ = plt.imshow(RandomInvert()(image)[0])

هر دوی این لایه ها را می توان همانطور که در گزینه های 1 و 2 در بالا توضیح داده شد استفاده کرد.
با استفاده از tf.image
ابزارهای پیش پردازش Keras فوق راحت هستند. اما، برای کنترل دقیقتر، میتوانید خطوط لوله یا لایههای افزایش داده خود را با استفاده از tf.data و tf.image . (شاید بخواهید تصویر افزونه های TensorFlow: Operations و TensorFlow I/O: Color Space Conversions را بررسی کنید.)
از آنجایی که مجموعه داده گل قبلاً با افزایش داده پیکربندی شده بود، بیایید آن را دوباره وارد کنیم تا تازه شروع شود:
(train_ds, val_ds, test_ds), metadata = tfds.load(
'tf_flowers',
split=['train[:80%]', 'train[80%:90%]', 'train[90%:]'],
with_info=True,
as_supervised=True,
)
بازیابی تصویر برای کار با:
image, label = next(iter(train_ds))
_ = plt.imshow(image)
_ = plt.title(get_label_name(label))
2022-01-26 05:09:59.918847: W tensorflow/core/kernels/data/cache_dataset_ops.cc:768] The calling iterator did not fully read the dataset being cached. In order to avoid unexpected truncation of the dataset, the partially cached contents of the dataset will be discarded. This can happen if you have an input pipeline similar to `dataset.cache().take(k).repeat()`. You should use `dataset.take(k).cache().repeat()` instead.

بیایید از تابع زیر برای تجسم و مقایسه تصاویر اصلی و افزوده شده در کنار هم استفاده کنیم:
def visualize(original, augmented):
fig = plt.figure()
plt.subplot(1,2,1)
plt.title('Original image')
plt.imshow(original)
plt.subplot(1,2,2)
plt.title('Augmented image')
plt.imshow(augmented)
افزایش داده ها
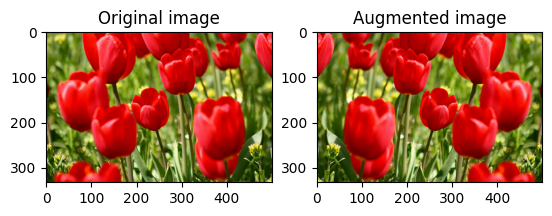
یک تصویر را ورق بزنید
با tf.image.flip_left_right یک تصویر را به صورت عمودی یا افقی برگردانید:
flipped = tf.image.flip_left_right(image)
visualize(image, flipped)
یک تصویر در مقیاس خاکستری
می توانید با tf.image.rgb_to_grayscale یک تصویر را در مقیاس خاکستری تغییر دهید:
grayscaled = tf.image.rgb_to_grayscale(image)
visualize(image, tf.squeeze(grayscaled))
_ = plt.colorbar()

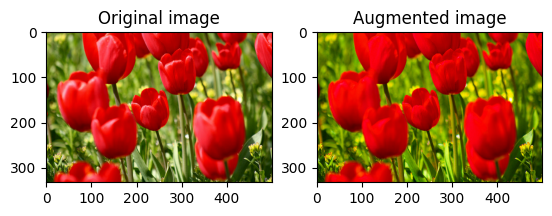
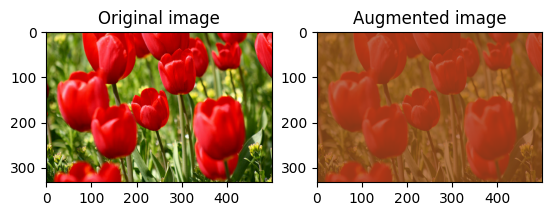
یک تصویر را اشباع کنید
با ارائه ضریب اشباع، یک تصویر را با tf.image.adjust_saturation اشباع کنید:
saturated = tf.image.adjust_saturation(image, 3)
visualize(image, saturated)
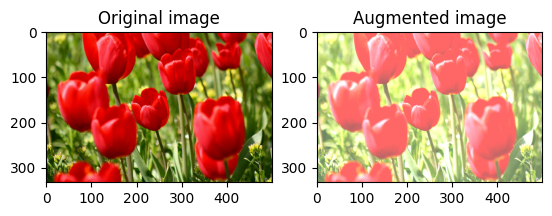
تغییر روشنایی تصویر
با ارائه ضریب روشنایی، روشنایی تصویر را با tf.image.adjust_brightness تغییر دهید:
bright = tf.image.adjust_brightness(image, 0.4)
visualize(image, bright)
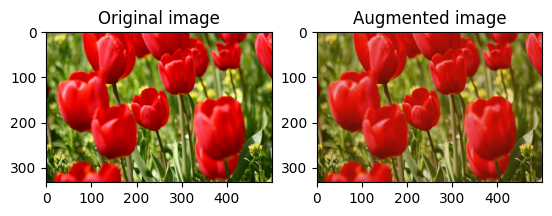
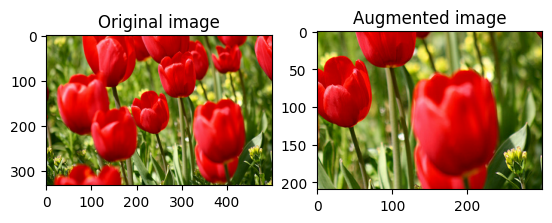
یک تصویر را در مرکز برش دهید
با استفاده از tf.image.central_crop تصویر را از مرکز به بالا به قسمت تصویر مورد نظر برش دهید:
cropped = tf.image.central_crop(image, central_fraction=0.5)
visualize(image, cropped)
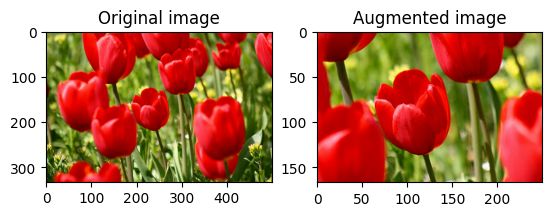
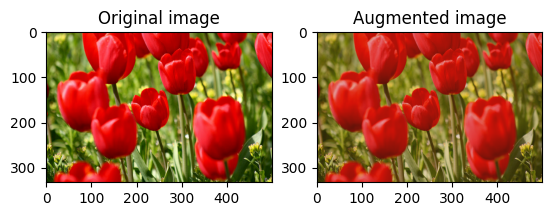
یک تصویر را بچرخانید
با tf.image.rot90 یک تصویر را 90 درجه بچرخانید:
rotated = tf.image.rot90(image)
visualize(image, rotated)

تبدیل های تصادفی
اعمال تبدیلهای تصادفی روی تصاویر میتواند به تعمیم و گسترش مجموعه داده کمک کند. tf.image API فعلی هشت عملیات تصویر تصادفی (ops) را ارائه میکند:
-
tf.image.stateless_random_brightness -
tf.image.stateless_random_contrast -
tf.image.stateless_random_crop -
tf.image.stateless_random_flip_left_right -
tf.image.stateless_random_flip_up_down -
tf.image.stateless_random_hue -
tf.image.stateless_random_jpeg_quality -
tf.image.stateless_random_saturation
این عملیات تصویر تصادفی کاملاً کاربردی هستند: خروجی فقط به ورودی بستگی دارد. این امر استفاده از آنها را در خطوط لوله ورودی با کارایی بالا و قطعی ساده می کند. آنها نیاز به یک seed دارند که در هر مرحله وارد شود. با توجه به seed یکسان، آنها نتایج یکسانی را مستقل از تعداد دفعات فراخوانی آنها برمیگردانند.
در بخش های زیر خواهید دید:
- نمونه هایی از استفاده از عملیات تصویر تصادفی برای تبدیل یک تصویر را مرور کنید.
- نحوه اعمال تبدیل های تصادفی به مجموعه داده آموزشی را نشان دهید.
به طور تصادفی روشنایی تصویر را تغییر دهید
به طور تصادفی روشنایی image با استفاده از tf.image.stateless_random_brightness با ارائه ضریب روشنایی و seed تغییر دهید. ضریب روشنایی به طور تصادفی در محدوده [-max_delta, max_delta) می شود و با seed داده شده مرتبط است.
for i in range(3):
seed = (i, 0) # tuple of size (2,)
stateless_random_brightness = tf.image.stateless_random_brightness(
image, max_delta=0.95, seed=seed)
visualize(image, stateless_random_brightness)
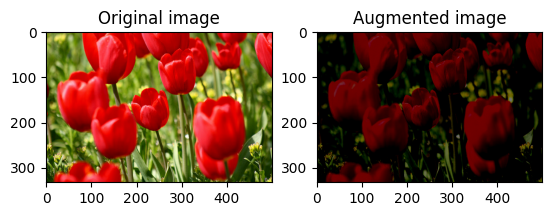
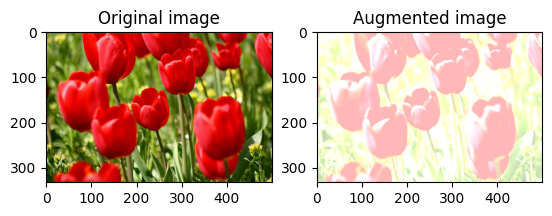
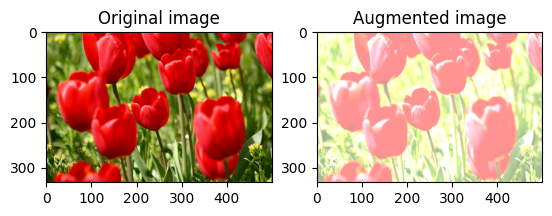
به طور تصادفی کنتراست تصویر را تغییر دهید
به طور تصادفی کنتراست image با استفاده از tf.image.stateless_random_contrast با ارائه محدوده کنتراست و seed تغییر دهید. محدوده کنتراست به طور تصادفی در بازه [lower, upper] انتخاب می شود و با seed داده شده مرتبط است.
for i in range(3):
seed = (i, 0) # tuple of size (2,)
stateless_random_contrast = tf.image.stateless_random_contrast(
image, lower=0.1, upper=0.9, seed=seed)
visualize(image, stateless_random_contrast)
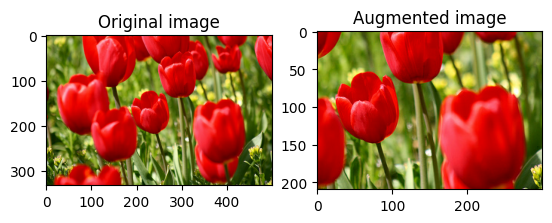
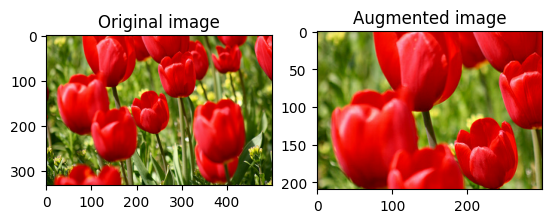
برش تصادفی یک تصویر
برش تصادفی image با استفاده از tf.image.stateless_random_crop با ارائه size و seed هدف. قسمتی که از image بریده می شود با یک افست تصادفی انتخاب شده است و با seed داده شده مرتبط است.
for i in range(3):
seed = (i, 0) # tuple of size (2,)
stateless_random_crop = tf.image.stateless_random_crop(
image, size=[210, 300, 3], seed=seed)
visualize(image, stateless_random_crop)
اعمال افزایش به یک مجموعه داده
بیایید ابتدا مجموعه داده های تصویر را دوباره بارگیری کنیم در صورتی که در بخش های قبلی اصلاح شده اند.
(train_datasets, val_ds, test_ds), metadata = tfds.load(
'tf_flowers',
split=['train[:80%]', 'train[80%:90%]', 'train[90%:]'],
with_info=True,
as_supervised=True,
)
در مرحله بعد، یک تابع کاربردی برای تغییر اندازه و تغییر مقیاس تصاویر تعریف کنید. این تابع برای یکسان سازی اندازه و مقیاس تصاویر در مجموعه داده استفاده می شود:
def resize_and_rescale(image, label):
image = tf.cast(image, tf.float32)
image = tf.image.resize(image, [IMG_SIZE, IMG_SIZE])
image = (image / 255.0)
return image, label
اجازه دهید تابع augment را نیز تعریف کنیم که می تواند تبدیل های تصادفی را روی تصاویر اعمال کند. این تابع در مرحله بعد روی مجموعه داده استفاده خواهد شد.
def augment(image_label, seed):
image, label = image_label
image, label = resize_and_rescale(image, label)
image = tf.image.resize_with_crop_or_pad(image, IMG_SIZE + 6, IMG_SIZE + 6)
# Make a new seed.
new_seed = tf.random.experimental.stateless_split(seed, num=1)[0, :]
# Random crop back to the original size.
image = tf.image.stateless_random_crop(
image, size=[IMG_SIZE, IMG_SIZE, 3], seed=seed)
# Random brightness.
image = tf.image.stateless_random_brightness(
image, max_delta=0.5, seed=new_seed)
image = tf.clip_by_value(image, 0, 1)
return image, label
گزینه 1: استفاده از tf.data.experimental.Counter
یک شی tf.data.experimental.Counter ایجاد کنید (بیایید آن را counter بنامیم) و Dataset.zip مجموعه داده را با (counter, counter) کنید. این اطمینان حاصل می کند که هر تصویر در مجموعه داده با یک مقدار منحصر به فرد (شکل (2,) ) بر اساس counter مرتبط می شود که بعداً می تواند به عنوان seed اولیه برای تبدیل های تصادفی به تابع augment شود.
# Create a `Counter` object and `Dataset.zip` it together with the training set.
counter = tf.data.experimental.Counter()
train_ds = tf.data.Dataset.zip((train_datasets, (counter, counter)))
تابع augment را به مجموعه داده آموزشی نگاشت:
train_ds = (
train_ds
.shuffle(1000)
.map(augment, num_parallel_calls=AUTOTUNE)
.batch(batch_size)
.prefetch(AUTOTUNE)
)
val_ds = (
val_ds
.map(resize_and_rescale, num_parallel_calls=AUTOTUNE)
.batch(batch_size)
.prefetch(AUTOTUNE)
)
test_ds = (
test_ds
.map(resize_and_rescale, num_parallel_calls=AUTOTUNE)
.batch(batch_size)
.prefetch(AUTOTUNE)
)
گزینه 2: استفاده از tf.random.Generator
- یک شی
tf.random.Generatorبا مقدارseedاولیه ایجاد کنید. فراخوانی تابعmake_seedsبر روی یک شی مولد، همیشه یک مقدارseedجدید و منحصر به فرد را برمی گرداند. - تابع wrapper را تعریف کنید که: 1) تابع
make_seedsرا فراخوانی کند. و 2) مقدارseedتازه تولید شده را به تابعaugmentبرای تبدیل های تصادفی منتقل می کند.
# Create a generator.
rng = tf.random.Generator.from_seed(123, alg='philox')
# Create a wrapper function for updating seeds.
def f(x, y):
seed = rng.make_seeds(2)[0]
image, label = augment((x, y), seed)
return image, label
تابع wrapper f را به مجموعه داده آموزشی و تابع resize_and_rescale به مجموعه های اعتبارسنجی و آزمایش نگاشت:
train_ds = (
train_datasets
.shuffle(1000)
.map(f, num_parallel_calls=AUTOTUNE)
.batch(batch_size)
.prefetch(AUTOTUNE)
)
val_ds = (
val_ds
.map(resize_and_rescale, num_parallel_calls=AUTOTUNE)
.batch(batch_size)
.prefetch(AUTOTUNE)
)
test_ds = (
test_ds
.map(resize_and_rescale, num_parallel_calls=AUTOTUNE)
.batch(batch_size)
.prefetch(AUTOTUNE)
)
این مجموعه داده ها اکنون می توانند برای آموزش یک مدل همانطور که قبلا نشان داده شده است استفاده شوند.
مراحل بعدی
این آموزش افزایش داده ها را با استفاده از لایه های پیش پردازش Keras و tf.image نشان می دهد.
- برای یادگیری نحوه گنجاندن لایه های پیش پردازش در مدل خود، به آموزش طبقه بندی تصاویر مراجعه کنید.
- همانطور که در آموزش طبقه بندی متن پایه نشان داده شده است، ممکن است علاقه مند به یادگیری این باشید که چگونه لایه های پیش پردازش می تواند به شما در طبقه بندی متن کمک کند.
- شما می توانید در این راهنما درباره
tf.dataاطلاعات بیشتری کسب کنید، و همچنین می توانید نحوه پیکربندی خطوط لوله ورودی خود را برای عملکرد در اینجا بیاموزید.