
| | |  مشاهده منبع در GitHub مشاهده منبع در GitHub | |
این آموزش نحوه بارگیری و پیش پردازش یک مجموعه داده تصویر را به سه روش نشان می دهد:
- ابتدا، از ابزارهای پیش پردازش Keras سطح بالا (مانند
tf.keras.utils.image_dataset_from_directory) و لایه ها (مانندtf.keras.layers.Rescaling) برای خواندن فهرستی از تصاویر روی دیسک استفاده خواهید کرد. - سپس، خط لوله ورودی خود را از ابتدا با استفاده از tf.data می نویسید.
- در نهایت، یک مجموعه داده را از کاتالوگ بزرگ موجود در TensorFlow Datasets دانلود خواهید کرد.
برپایی
import numpy as np
import os
import PIL
import PIL.Image
import tensorflow as tf
import tensorflow_datasets as tfds
print(tf.__version__)
2.8.0-rc1
مجموعه داده گل ها را دانلود کنید
این آموزش از مجموعه داده ای از چندین هزار عکس گل استفاده می کند. مجموعه داده گلها شامل پنج زیرمجموعه است، یکی در هر کلاس:
flowers_photos/
daisy/
dandelion/
roses/
sunflowers/
tulips/
import pathlib
dataset_url = "https://storage.googleapis.com/download.tensorflow.org/example_images/flower_photos.tgz"
data_dir = tf.keras.utils.get_file(origin=dataset_url,
fname='flower_photos',
untar=True)
data_dir = pathlib.Path(data_dir)
پس از دانلود (218 مگابایت)، اکنون باید یک کپی از عکس های گل در دسترس داشته باشید. 3670 تصویر در کل وجود دارد:
image_count = len(list(data_dir.glob('*/*.jpg')))
print(image_count)
3670
هر دایرکتوری حاوی تصاویری از آن نوع گل است. در اینجا چند گل رز وجود دارد:
roses = list(data_dir.glob('roses/*'))
PIL.Image.open(str(roses[0]))

roses = list(data_dir.glob('roses/*'))
PIL.Image.open(str(roses[1]))

داده ها را با استفاده از ابزار Keras بارگیری کنید
بیایید این تصاویر را با استفاده از ابزار مفید tf.keras.utils.image_dataset_from_directory از روی دیسک بارگذاری کنیم.
یک مجموعه داده ایجاد کنید
چند پارامتر برای لودر تعریف کنید:
batch_size = 32
img_height = 180
img_width = 180
استفاده از تقسیم اعتبار در هنگام توسعه مدل خود تمرین خوبی است. شما از 80 درصد تصاویر برای آموزش و 20 درصد برای اعتبار سنجی استفاده خواهید کرد.
train_ds = tf.keras.utils.image_dataset_from_directory(
data_dir,
validation_split=0.2,
subset="training",
seed=123,
image_size=(img_height, img_width),
batch_size=batch_size)
Found 3670 files belonging to 5 classes. Using 2936 files for training.
val_ds = tf.keras.utils.image_dataset_from_directory(
data_dir,
validation_split=0.2,
subset="validation",
seed=123,
image_size=(img_height, img_width),
batch_size=batch_size)
Found 3670 files belonging to 5 classes. Using 734 files for validation.
می توانید نام کلاس ها را در ویژگی class_names در این مجموعه داده ها پیدا کنید.
class_names = train_ds.class_names
print(class_names)
['daisy', 'dandelion', 'roses', 'sunflowers', 'tulips']
داده ها را تجسم کنید
در اینجا نه تصویر اول از مجموعه داده آموزشی آمده است.
import matplotlib.pyplot as plt
plt.figure(figsize=(10, 10))
for images, labels in train_ds.take(1):
for i in range(9):
ax = plt.subplot(3, 3, i + 1)
plt.imshow(images[i].numpy().astype("uint8"))
plt.title(class_names[labels[i]])
plt.axis("off")
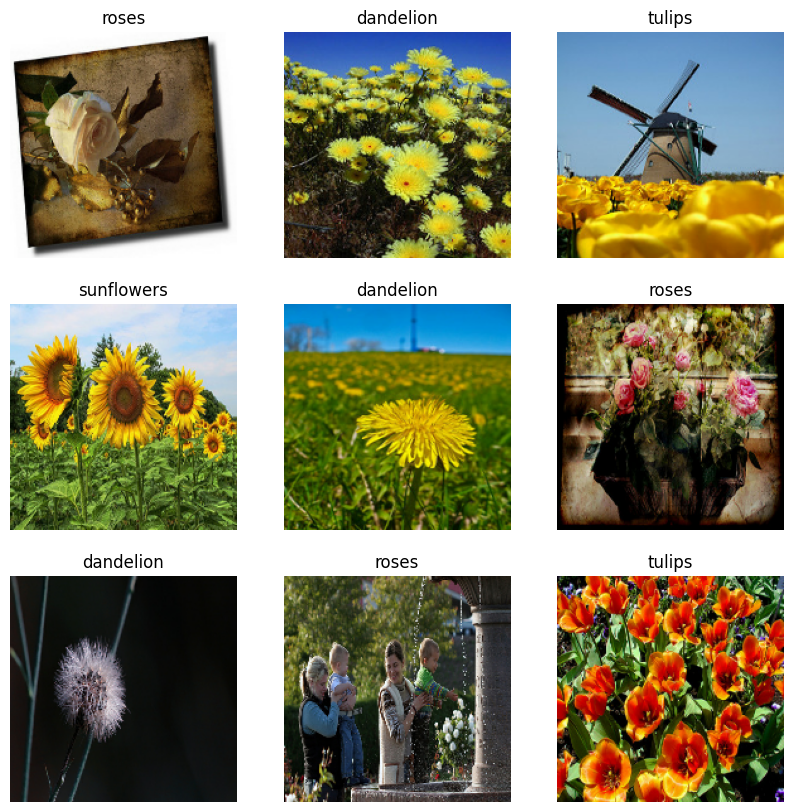
شما می توانید یک مدل را با استفاده از این مجموعه داده ها با ارسال آنها به model.fit (در ادامه در این آموزش نشان داده شده است) آموزش دهید. اگر دوست دارید، میتوانید به صورت دستی روی مجموعه داده تکرار کنید و دستهای از تصاویر را بازیابی کنید:
for image_batch, labels_batch in train_ds:
print(image_batch.shape)
print(labels_batch.shape)
break
(32, 180, 180, 3) (32,)
image_batch تانسور شکل (32, 180, 180, 3) است. این مجموعه ای از 32 تصویر به شکل 180x180x3 است (بعد آخر به کانال های رنگی RGB اشاره دارد). label_batch یک تانسور شکل (32,) است، اینها برچسب های مربوط به 32 تصویر هستند.
شما می توانید .numpy() را در هر یک از این تانسورها فراخوانی کنید تا آنها را به numpy.ndarray تبدیل کنید.
داده ها را استاندارد کنید
مقادیر کانال RGB در محدوده [0, 255] است. این برای یک شبکه عصبی ایده آل نیست. به طور کلی باید به دنبال کوچک کردن مقادیر ورودی خود باشید.
در اینجا، با استفاده از tf.keras.layers.Rescaling ، مقادیر را در محدوده [0, 1] استاندارد میکنید:
normalization_layer = tf.keras.layers.Rescaling(1./255)
دو روش برای استفاده از این لایه وجود دارد. با فراخوانی Dataset.map می توانید آن را به مجموعه داده اعمال کنید:
normalized_ds = train_ds.map(lambda x, y: (normalization_layer(x), y))
image_batch, labels_batch = next(iter(normalized_ds))
first_image = image_batch[0]
# Notice the pixel values are now in `[0,1]`.
print(np.min(first_image), np.max(first_image))
0.0 0.96902645
یا، می توانید لایه را در داخل تعریف مدل خود قرار دهید تا استقرار را ساده کنید. در اینجا از روش دوم استفاده خواهید کرد.
مجموعه داده را برای عملکرد پیکربندی کنید
بیایید مطمئن شویم که از واکشی اولیه بافر استفاده می کنیم تا بتوانید بدون مسدود شدن ورودی/خروجی، داده ها را از دیسک به دست آورید. این دو روش مهم هستند که باید هنگام بارگیری داده ها از آنها استفاده کنید:
-
Dataset.cacheتصاویر را پس از بارگیری از دیسک در اولین دوره در حافظه نگه می دارد. این اطمینان حاصل می کند که مجموعه داده در حین آموزش مدل شما به یک گلوگاه تبدیل نمی شود. اگر مجموعه داده شما بیش از حد بزرگ است که نمی تواند در حافظه قرار بگیرد، می توانید از این روش برای ایجاد یک حافظه کش عملکردی روی دیسک نیز استفاده کنید. -
Dataset.prefetchبا پیش پردازش داده ها و اجرای مدل در حین آموزش همپوشانی دارد.
خوانندگان علاقه مند می توانند با راهنمای tf.data API اطلاعات بیشتری در مورد هر دو روش و همچنین نحوه کش کردن داده ها در دیسک در بخش Prefetching از عملکرد بهتر کسب کنند.
AUTOTUNE = tf.data.AUTOTUNE
train_ds = train_ds.cache().prefetch(buffer_size=AUTOTUNE)
val_ds = val_ds.cache().prefetch(buffer_size=AUTOTUNE)
یک مدل تربیت کنید
برای کامل بودن، نحوه آموزش یک مدل ساده را با استفاده از مجموعه داده هایی که به تازگی آماده کرده اید نشان خواهید داد.
مدل متوالی از سه بلوک کانولوشن ( tf.keras.layers.Conv2D ) با یک لایه تجمع حداکثر ( tf.keras.layers.MaxPooling2D ) در هر یک از آنها تشکیل شده است. یک لایه کاملاً متصل ( tf.keras.layers.Dense ) با 128 واحد در بالای آن وجود دارد که توسط یک تابع فعال سازی ReLU ( 'relu' ) فعال می شود. این مدل به هیچ وجه تنظیم نشده است - هدف این است که با استفاده از مجموعه دادههایی که ایجاد کردهاید، مکانیک را به شما نشان دهد. برای کسب اطلاعات بیشتر در مورد طبقه بندی تصاویر، به آموزش طبقه بندی تصاویر مراجعه کنید.
num_classes = 5
model = tf.keras.Sequential([
tf.keras.layers.Rescaling(1./255),
tf.keras.layers.Conv2D(32, 3, activation='relu'),
tf.keras.layers.MaxPooling2D(),
tf.keras.layers.Conv2D(32, 3, activation='relu'),
tf.keras.layers.MaxPooling2D(),
tf.keras.layers.Conv2D(32, 3, activation='relu'),
tf.keras.layers.MaxPooling2D(),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dense(num_classes)
])
تابع از دست دادن tf.keras.optimizers.Adam و tf.keras.losses.SparseCategoricalCrossentropy را انتخاب کنید. برای مشاهده دقت آموزش و اعتبارسنجی برای هر دوره آموزشی، آرگومان metrics را به Model.compile کنید.
model.compile(
optimizer='adam',
loss=tf.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
model.fit(
train_ds,
validation_data=val_ds,
epochs=3
)
Epoch 1/3 92/92 [==============================] - 4s 21ms/step - loss: 1.3091 - accuracy: 0.4281 - val_loss: 1.0982 - val_accuracy: 0.5599 Epoch 2/3 92/92 [==============================] - 1s 12ms/step - loss: 1.0196 - accuracy: 0.5879 - val_loss: 0.9572 - val_accuracy: 0.6213 Epoch 3/3 92/92 [==============================] - 1s 12ms/step - loss: 0.8455 - accuracy: 0.6775 - val_loss: 0.8839 - val_accuracy: 0.6512 <keras.callbacks.History at 0x7ff10c168850>
ممکن است متوجه شوید که دقت اعتبارسنجی در مقایسه با دقت آموزشی پایین است، که نشان میدهد مدل شما بیش از حد مناسب است. در این آموزش میتوانید در مورد اضافه کردن و نحوه کاهش آن بیشتر بدانید.
استفاده از tf.data برای کنترل دقیق تر
ابزار پیش پردازش Keras فوق — tf.keras.utils.image_dataset_from_directory — راهی مناسب برای ایجاد tf.data.Dataset از فهرست تصاویر است.
برای کنترل دانه های دقیق تر، می توانید خط لوله ورودی خود را با استفاده از tf.data . این بخش نحوه انجام این کار را نشان می دهد، با مسیرهای فایل از فایل TGZ که قبلا دانلود کرده اید شروع می شود.
list_ds = tf.data.Dataset.list_files(str(data_dir/'*/*'), shuffle=False)
list_ds = list_ds.shuffle(image_count, reshuffle_each_iteration=False)
for f in list_ds.take(5):
print(f.numpy())
b'/home/kbuilder/.keras/datasets/flower_photos/roses/14267691818_301aceda07.jpg' b'/home/kbuilder/.keras/datasets/flower_photos/daisy/2641151167_3bf1349606_m.jpg' b'/home/kbuilder/.keras/datasets/flower_photos/sunflowers/6495554833_86eb8faa8e_n.jpg' b'/home/kbuilder/.keras/datasets/flower_photos/tulips/4578030672_e6aefd45af.jpg' b'/home/kbuilder/.keras/datasets/flower_photos/dandelion/144686365_d7e96941ee_n.jpg'
از ساختار درختی فایل ها می توان برای کامپایل لیست class_names استفاده کرد.
class_names = np.array(sorted([item.name for item in data_dir.glob('*') if item.name != "LICENSE.txt"]))
print(class_names)
['daisy' 'dandelion' 'roses' 'sunflowers' 'tulips']
مجموعه داده را به مجموعه های آموزشی و اعتبار سنجی تقسیم کنید:
val_size = int(image_count * 0.2)
train_ds = list_ds.skip(val_size)
val_ds = list_ds.take(val_size)
می توانید طول هر مجموعه داده را به صورت زیر چاپ کنید:
print(tf.data.experimental.cardinality(train_ds).numpy())
print(tf.data.experimental.cardinality(val_ds).numpy())
2936 734
یک تابع کوتاه بنویسید که یک مسیر فایل را به یک جفت (img, label) تبدیل می کند:
def get_label(file_path):
# Convert the path to a list of path components
parts = tf.strings.split(file_path, os.path.sep)
# The second to last is the class-directory
one_hot = parts[-2] == class_names
# Integer encode the label
return tf.argmax(one_hot)
def decode_img(img):
# Convert the compressed string to a 3D uint8 tensor
img = tf.io.decode_jpeg(img, channels=3)
# Resize the image to the desired size
return tf.image.resize(img, [img_height, img_width])
def process_path(file_path):
label = get_label(file_path)
# Load the raw data from the file as a string
img = tf.io.read_file(file_path)
img = decode_img(img)
return img, label
از Dataset.map برای ایجاد مجموعه داده ای از image, label استفاده کنید:
# Set `num_parallel_calls` so multiple images are loaded/processed in parallel.
train_ds = train_ds.map(process_path, num_parallel_calls=AUTOTUNE)
val_ds = val_ds.map(process_path, num_parallel_calls=AUTOTUNE)
for image, label in train_ds.take(1):
print("Image shape: ", image.numpy().shape)
print("Label: ", label.numpy())
Image shape: (180, 180, 3) Label: 1
پیکربندی مجموعه داده برای عملکرد
برای آموزش یک مدل با این مجموعه داده، داده های زیر را می خواهید:
- خوب به هم ریخته شدن.
- دسته بندی شود.
- دسته ها در اسرع وقت در دسترس قرار می گیرند.
این ویژگی ها را می توان با استفاده از tf.data API اضافه کرد. برای جزئیات بیشتر، به راهنمای عملکرد خط لوله ورودی مراجعه کنید.
def configure_for_performance(ds):
ds = ds.cache()
ds = ds.shuffle(buffer_size=1000)
ds = ds.batch(batch_size)
ds = ds.prefetch(buffer_size=AUTOTUNE)
return ds
train_ds = configure_for_performance(train_ds)
val_ds = configure_for_performance(val_ds)
داده ها را تجسم کنید
شما می توانید این مجموعه داده را مشابه آنچه که قبلا ایجاد کرده اید تجسم کنید:
image_batch, label_batch = next(iter(train_ds))
plt.figure(figsize=(10, 10))
for i in range(9):
ax = plt.subplot(3, 3, i + 1)
plt.imshow(image_batch[i].numpy().astype("uint8"))
label = label_batch[i]
plt.title(class_names[label])
plt.axis("off")
2022-01-26 06:29:45.209901: W tensorflow/core/kernels/data/cache_dataset_ops.cc:768] The calling iterator did not fully read the dataset being cached. In order to avoid unexpected truncation of the dataset, the partially cached contents of the dataset will be discarded. This can happen if you have an input pipeline similar to `dataset.cache().take(k).repeat()`. You should use `dataset.take(k).cache().repeat()` instead.
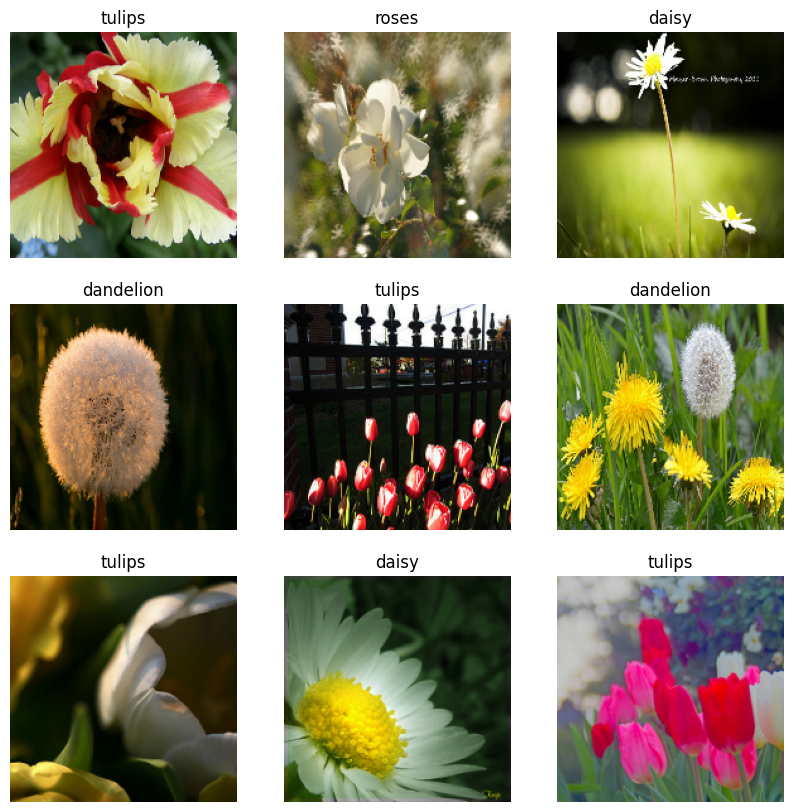
به آموزش مدل ادامه دهید
شما اکنون به صورت دستی یک tf.data.Dataset مشابه با مجموعه ایجاد شده توسط tf.keras.utils.image_dataset_from_directory بالا ساخته اید. می توانید آموزش مدل را با آن ادامه دهید. مانند قبل، فقط برای چند دوره تمرین خواهید کرد تا زمان اجرا را کوتاه نگه دارید.
model.fit(
train_ds,
validation_data=val_ds,
epochs=3
)
Epoch 1/3 92/92 [==============================] - 3s 21ms/step - loss: 0.7305 - accuracy: 0.7245 - val_loss: 0.7311 - val_accuracy: 0.7139 Epoch 2/3 92/92 [==============================] - 1s 13ms/step - loss: 0.5279 - accuracy: 0.8069 - val_loss: 0.7021 - val_accuracy: 0.7316 Epoch 3/3 92/92 [==============================] - 1s 13ms/step - loss: 0.3739 - accuracy: 0.8644 - val_loss: 0.8266 - val_accuracy: 0.6948 <keras.callbacks.History at 0x7ff0ee071f10>
استفاده از مجموعه داده های TensorFlow
تا کنون، این آموزش بر روی بارگذاری اطلاعات از روی دیسک متمرکز شده است. همچنین میتوانید با کاوش در کاتالوگ بزرگ مجموعههای داده با دانلود آسان در TensorFlow Datasets ، یک مجموعه داده برای استفاده پیدا کنید.
همانطور که قبلاً مجموعه داده Flowers را از دیسک بارگیری کرده اید، اکنون آن را با TensorFlow Datasets وارد می کنیم.
مجموعه داده Flowers را با استفاده از TensorFlow Datasets دانلود کنید:
(train_ds, val_ds, test_ds), metadata = tfds.load(
'tf_flowers',
split=['train[:80%]', 'train[80%:90%]', 'train[90%:]'],
with_info=True,
as_supervised=True,
)
مجموعه داده گل دارای پنج کلاس است:
num_classes = metadata.features['label'].num_classes
print(num_classes)
5
بازیابی تصویر از مجموعه داده:
get_label_name = metadata.features['label'].int2str
image, label = next(iter(train_ds))
_ = plt.imshow(image)
_ = plt.title(get_label_name(label))
2022-01-26 06:29:54.281352: W tensorflow/core/kernels/data/cache_dataset_ops.cc:768] The calling iterator did not fully read the dataset being cached. In order to avoid unexpected truncation of the dataset, the partially cached contents of the dataset will be discarded. This can happen if you have an input pipeline similar to `dataset.cache().take(k).repeat()`. You should use `dataset.take(k).cache().repeat()` instead.

مانند قبل، به یاد داشته باشید که مجموعههای آموزشی، اعتبارسنجی و تست را برای عملکرد دستهبندی، مخلوط کردن و پیکربندی کنید:
train_ds = configure_for_performance(train_ds)
val_ds = configure_for_performance(val_ds)
test_ds = configure_for_performance(test_ds)
با مراجعه به آموزش افزایش داده ها می توانید یک نمونه کامل از کار با مجموعه داده Flowers و TensorFlow Datasets را بیابید.
مراحل بعدی
این آموزش دو راه برای بارگذاری تصاویر از روی دیسک را نشان می دهد. ابتدا یاد گرفتید که چگونه یک مجموعه داده تصویر را با استفاده از لایه ها و ابزارهای پیش پردازش Keras بارگیری و پیش پردازش کنید. سپس، نحوه نوشتن خط لوله ورودی را از ابتدا با استفاده از tf.data . در نهایت، نحوه دانلود مجموعه داده از TensorFlow Datasets را یاد گرفتید.
برای مراحل بعدی شما:
- می توانید نحوه افزودن افزایش داده را بیاموزید.
- برای کسب اطلاعات بیشتر در مورد
tf.data، می توانید به tf.data مراجعه کنید: راهنمای خطوط لوله ورودی Build TensorFlow .